SERVER系列
PC系列



LR-LINK注重人才的自主培养,形成在内部竞聘和培养文化,并希望为员工提供最好的学习和持续发展的环境。也许,你是久经职场的精英;亦或,你是初出茅庐的菜鸟;不过没关系,只要你确实有料,同时有实现自我价值的激情,请留下你的简历,和我们一起锐意开拓,引领创新。


PCIe Switch技术如何解决AI服务器扩展难题
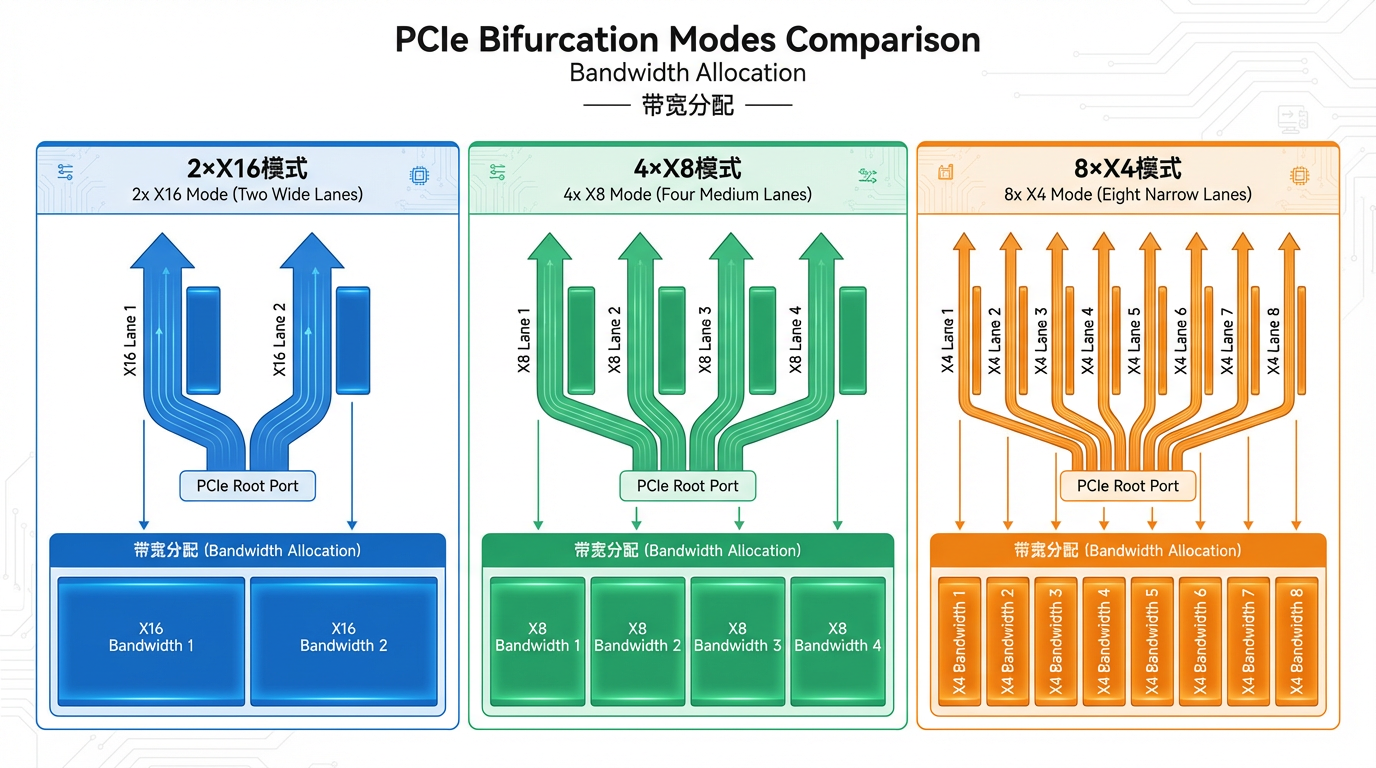
深度解析LRSV9500-4I在X4/X8/X16模式下的应用价值
随着AI大模型训练、高性能计算以及云计算的迅猛发展,企业对服务器GPU算力与存储性能的需求呈现出爆发式增长态势。然而,传统服务器架构在扩展能力上存在诸多瓶颈,例如PCIe插槽数量有限、GPU与SSD难以兼顾、扩展方案缺乏灵活性等,这些问题严重制约了业务创新。本文将深入剖析这些行业痛点,并展示LR-LINK LRSV9500-4I如何通过灵活的X4/X8/X16 Bifurcation模式为企业提供一站式扩展解决方案。
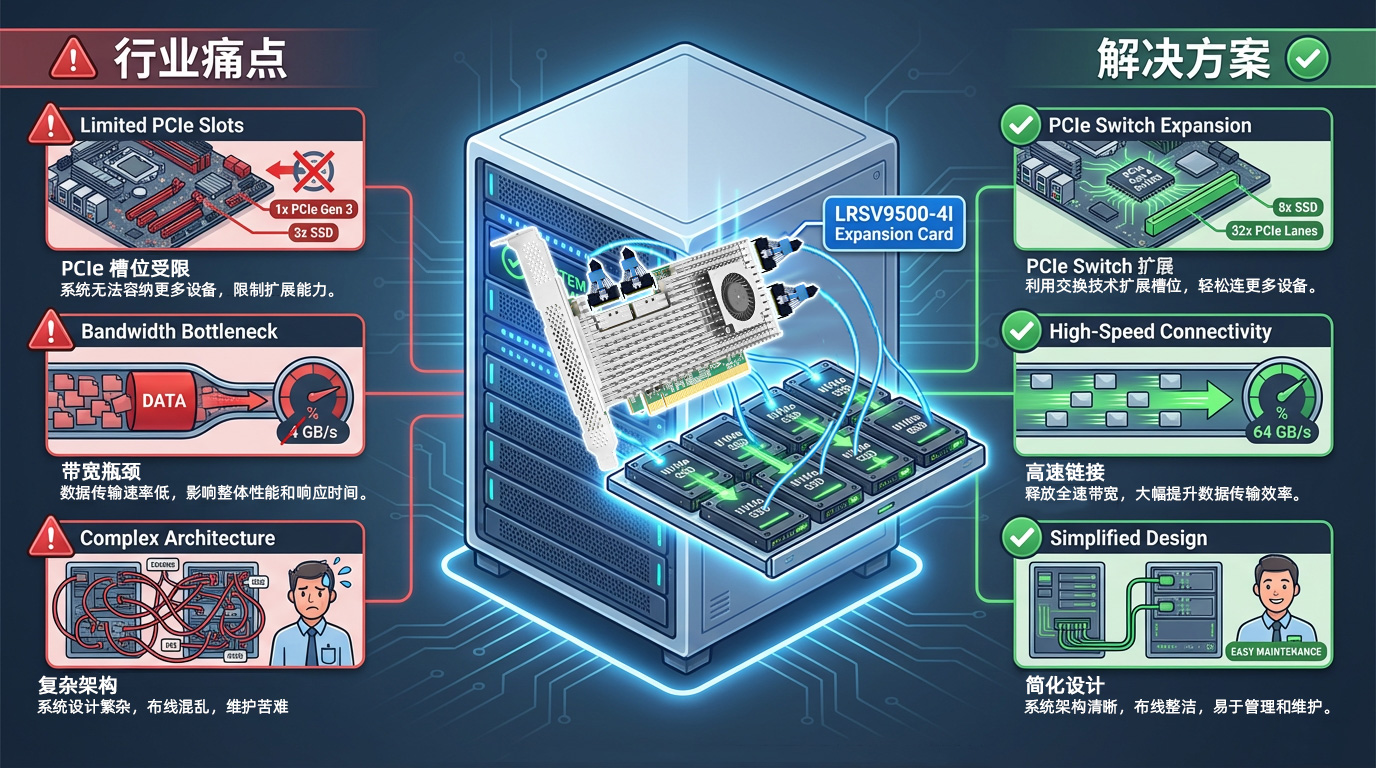
图1:服务器存储扩展痛点与PCIe Switch解决方案
现代服务器主板通常仅提供4—8个PCIe插槽,而这些插槽需要同时满足网卡、GPU、NVMe SSD、RAID卡等多种外设的需求。在AI训练场景中,一台服务器可能需要4—8块GPU显卡,再加上高速存储设备,PCIe插槽数量往往成为最大的制约因素。
• GPU与SSD难以同时部署,需在算力与存储之间做出权衡
• 不得不采购更多服务器,致使TCO成本显著提高
• 机柜空间迅速耗尽,数据中心资源利用率较低
LRSV9500-4I通过Broadcom PEX89048 PCIe Switch芯片,将单个PCIe 5.0 x16插槽扩展为4个MCIO 8I接口。在X4模式下可连接8路NVMe SSD;在X16模式下可连接2路高端GPU显卡。仅占用1个PCIe插槽,便可达成800%的扩展效率提升。
AI训练场景对GPU和高速存储都有极高要求。GPU需要处理海量数据,而传统SAS/SATA存储的带宽和IOPS无法满足需求。然而,主板的PCIe插槽被GPU占据后,就没有足够的接口来部署NVMe SSD阵列。
• 在进行大模型训练时,GPU算力利用率通常低于峰值算力,例如在千卡GPU集群中,利用率约为59%,而在万卡GPU集群中,利用率约为55.2%。
• 训练数据读取成为制约因素,模型迭代周期变长
通过X8混合模式,LRSV9500-4I可以同时支持GPU和NVMe SSD。例如,采用2×X8连接GPU,剩余的2×X8连接2路NVMe SSD作为本地缓存。这样GPU可以直接从高速本地存储读取数据,训练效率提升3-5倍。
PCIe 5.0标准的信号速率达到了32GT/s,这一速度的翻倍意味着对信号完整性的要求极为严格,以确保数据传输的准确性和效率。长距离传输、劣质线缆或连接器都会导致信号衰减、误码率上升,严重时会导致设备无法识别或频繁掉线。
• 在GPU训练过程中,若出现掉卡情况,会导致数天的计算成果丢失
• 存储设备降速运行,速度从PCIe 5.0降至4.0,甚至降至3.0
• 系统不稳定,出现蓝屏死机现象,进而影响业务连续性
LRSV9500-4I采用高规格PCB设计、优质连接器和信号优化技术,确保PCIe 5.0全速率稳定运行,PCIe 5.0技术能够提供高达14,000MB/s的顺序读写速度,以及在正确配置下的最佳性能。MCIO接口提供可靠的物理连接,配合认证线缆可有效降低误码率,保障7×24小时稳定运行。
在多GPU训练场景下,GPU之间的互联拓扑会直接影响训练效率。传统方案依赖CPU所提供的PCIe通道,多卡之间的通信需经过CPU,这会导致带宽受限且延迟较高。
• 由于GPU间通信带宽存在不足的情况,导致分布式训练的效率较为低下
• 在进行大规模集群扩展时面临困难
LRSV9500-4I在X16模式下,GPU借助Switch实现高效的P2P通信,有效提升多卡训练的效率。
跨主机集群借助支持 RoCE v2(RDMA over Converged Ethernet) 的网卡,让 GPU 绕过 CPU,直接通过网络适配器将数据写入远程 GPU 的显存,多台服务器直接互联,进而达成内存共享以及高速数据交换的目的。
|
对比维度 |
传统方案 |
LRSV9500-4I方案 |
|
扩展能力 |
1插槽=1设备 |
1插槽=8 SSD或2 GPU |
|
配置灵活性 |
固定功能 |
X4/X8/X16可切换 |
|
GPU+SSD兼顾 |
难以同时满足 |
X8模式完美支持 |
|
PCIe 5.0支持 |
部分支持 |
完整32GT/s支持 |
|
多GPU互联 |
依赖CPU转发 |
P2P通信 |
服务器GPU与存储扩展的痛点本质上是有限资源与无限需求之间的矛盾。LRSV9500-4I通过PCIe Switch技术和灵活的X4/X8/X16 Bifurcation模式,为企业提供了高效的解决路径。无论是AI训练、高性能计算,还是大数据分析、视频制作,LRSV9500-4I都能提供卓越的扩展能力和投资保护。
研发中心地址:深圳市龙岗区龙城街道远洋新天地T10栋14楼
制造中心地址:深圳市龙岗区龙岗街道新生绿谷1B栋9-11楼
邮 箱: info@lr-link.com
技术支持: 19924451883


 产品咨询
产品咨询 技术支持
技术支持
 服务电话
服务电话服务热线:
4000-588-108