SERVER系列
PC系列



LR-LINK注重人才的自主培养,形成在内部竞聘和培养文化,并希望为员工提供最好的学习和持续发展的环境。也许,你是久经职场的精英;亦或,你是初出茅庐的菜鸟;不过没关系,只要你确实有料,同时有实现自我价值的激情,请留下你的简历,和我们一起锐意开拓,引领创新。


在金融交易领域,网络延迟是决定交易成败的核心竞争力。高频交易(HFT)系统的每一次买卖决策窗口可能只有数微秒,股票价格在毫秒级别即可发生显著波动——1毫秒的延迟差距,在大规模量化交易中可能意味着每年数亿元的利润损失。从订单管理系统(OMS)到交易所撮合引擎,从风险控制系统到清算结算平台,金融基础设施的每个网络节点都在追求更低的延迟。联瑞电子(LR-LINK)针对金融行业超低延迟场景,提供从万兆到百兆级别的全系列低延迟网卡解决方案,并支持IEEE 1588/PTP硬件时间戳、DPDK用户态驱动和信创合规等关键技术特性,为金融机构的交易系统提供坚实的网络基础设施。
金融交易对网络延迟的要求从业务类型来看差异显著,但对"确定性低延迟"(即不仅要求平均延迟低,更要求延迟抖动小)的要求是共同的:
高频交易(HFT):高频交易策略利用市场微观结构中的价格不一致性获利,通常基于算法在毫秒乃至微秒内完成决策和下单。主要交易所(上交所、深交所、中金所)的撮合系统延迟已降至数十微秒级别,对接交易所的专线网络通常要求端到端延迟不超过50~100微秒。在这个量级上,任何额外的软件处理开销(如内核协议栈的网络路径)都是不可接受的,必须采用Kernel Bypass(内核旁路)技术。
量化交易:与高频交易不同,量化交易的交易信号往往基于较复杂的模型计算,决策周期从数毫秒到数百毫秒不等。但在同等策略质量下,更低的延迟仍意味着更好的执行价格(滑点更小),尤其是在大宗交易拆单和算法执行过程中,毫秒级的延迟优势会被放大为显著的成本差异。
风险控制系统:实时风控系统需要在每笔交易指令提交交易所之前,完成账户资金校验、持仓限制检查、单品种暴露度计算等一系列风控规则验证。风控计算本身可以做到数微秒,但如果网络延迟过高,风控环节就会成为整个交易链路的瓶颈,反而拖慢了正常交易的执行效率。
行情数据订阅:交易系统的决策依赖于高频实时行情数据的摄取和处理。沪深两市的实时行情数据速率可达每秒数万条消息,行情系统在处理如此高速的UDP组播数据流时,网卡的多队列处理能力(RSS/RPS)和硬件过滤功能(NTUPLE)显得至关重要,可以将无效消息在硬件层面过滤丢弃,大幅降低主机CPU的处理压力。
在金融交易系统中,网络延迟由多个层面叠加构成,理解每个层面的延迟来源是选择正确技术方案的前提:
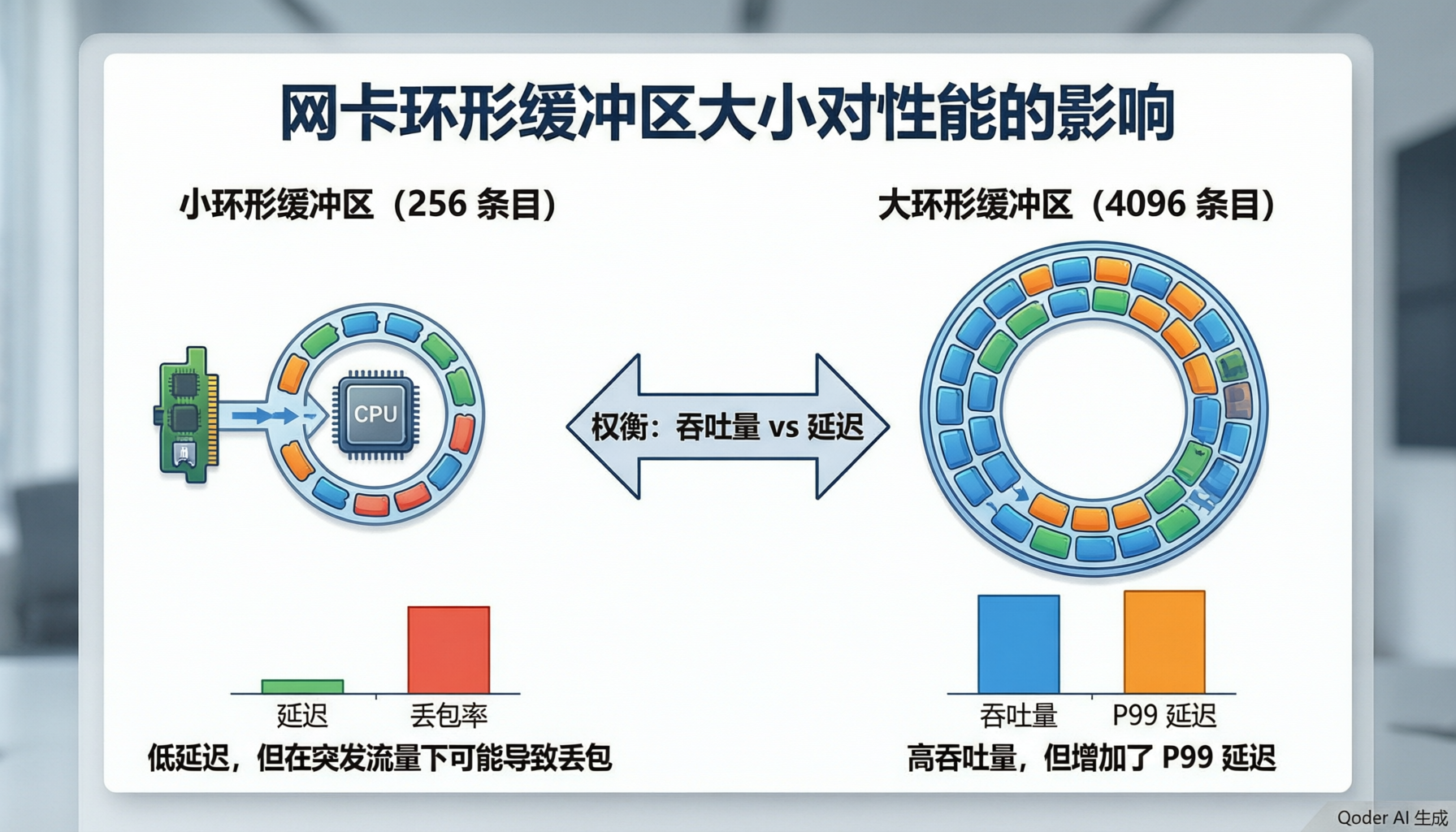
内核协议栈开销(最大影响因素):Linux内核TCP/IP协议栈每处理一个数据包大约需要经过20~30个内核函数调用,引入30~50微秒的内核处理延迟(在高负载下可能超过100微秒)。Kernel Bypass技术(DPDK、RDMA等)通过将数据包处理完全移至用户态,绕过内核协议栈,将延迟压缩至1~5微秒。
网卡硬件延迟:网卡本身的处理延迟(从数据包DMA到主机内存到触发中断/轮询通知)通常在1~3微秒。支持Cut-Through(直通)转发模式的交换机和网卡,相比Store-and-Forward(存储转发)模式可进一步降低数微秒的延迟。
物理链路延迟:光纤传播速度约为2/3光速(约20万公里/秒),每公里引入约5微秒的传播延迟。金融机构托管服务器时通常选择与交易所机房最近的位置(共址托管,co-location),以最小化物理距离带来的传播延迟。
时钟同步精度:量化交易系统需要对每笔订单和成交记录打上精确的时间戳,用于合规审计和策略分析。IEEE 1588 PTP(精确时间协议)硬件时间戳支持可以将时钟同步精度提升至亚微秒级别(而NTP协议的同步精度通常只有毫秒级),这对于监管机构要求的时间戳精度(通常要求纳秒级)至关重要。
金融级低延迟网卡需要在硬件设计和驱动软件层面都具备以下核心技术能力:
DPDK用户态驱动:DPDK(Data Plane Development Kit)是Intel开源的高性能数据面开发套件,通过PMD(Poll Mode Driver,轮询模式驱动)完全绕过Linux内核网络栈,由用户态程序直接控制网卡硬件收发包。在DPDK模式下,网卡驱动不再使用中断通知机制,而是CPU核心持续轮询网卡Rx Queue中的新数据包,将端到端延迟从数十微秒降低至1~2微秒。Intel igb/ixgbe/i40e/ice均有完整的DPDK PMD驱动支持,联瑞电子基于Intel芯片的网卡产品可无缝接入DPDK生态。
硬件时间戳(IEEE 1588/PTP):支持IEEE 1588-2008(PTP v2)的网卡可以在硬件层面捕获数据包到达的精确时间,精度可达纳秒级。相比软件时间戳(在内核处理数据包时记录时间,受调度抖动影响),硬件时间戳消除了软件引入的时间不确定性,是金融监管合规的重要技术保障。Intel X710/XXV710/E810系列网卡均内置了PTP硬件时间戳支持。
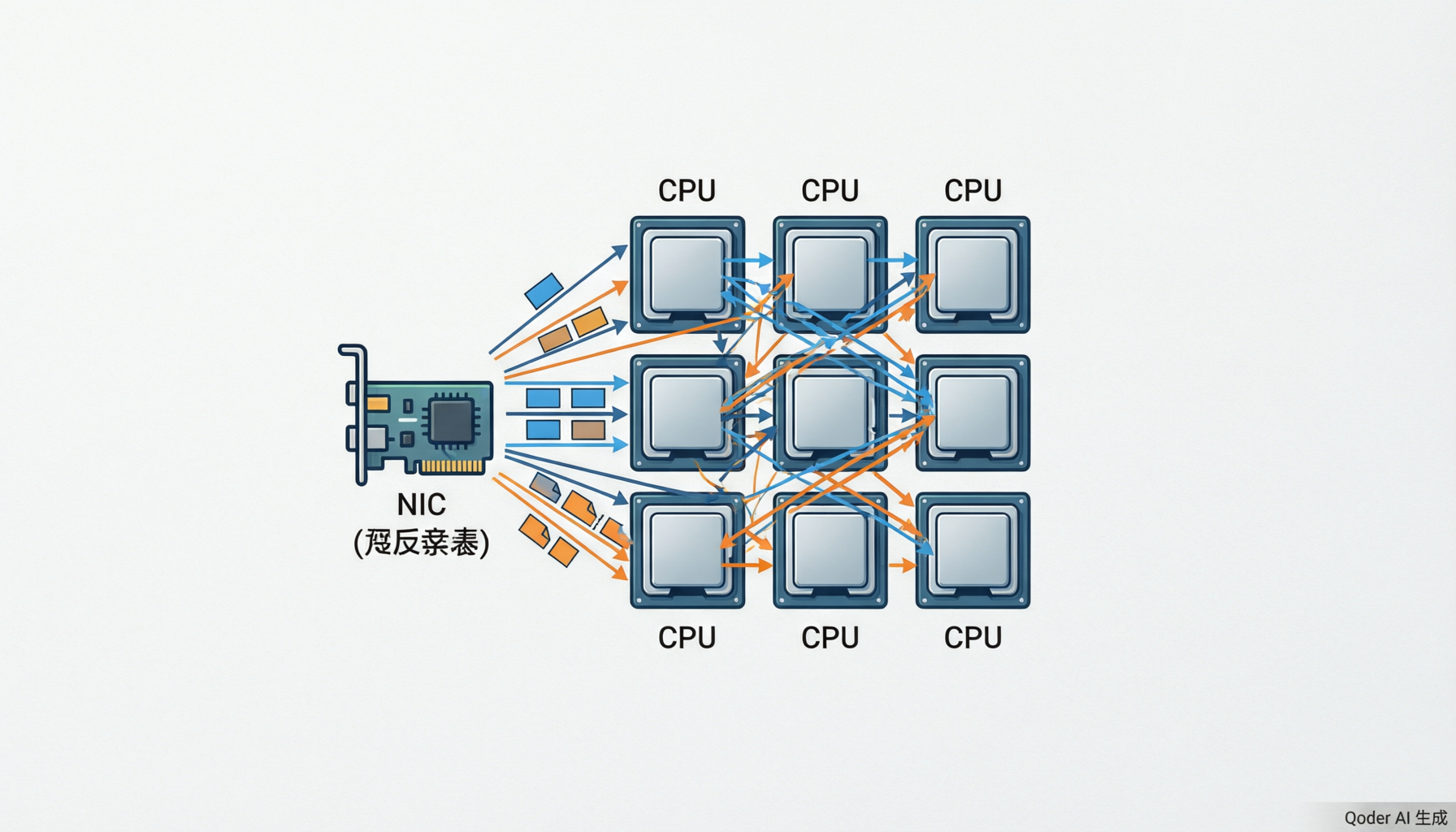
RSS多队列与流分类:RSS(Receive Side Scaling)允许网卡根据数据包的五元组(源IP、目的IP、协议、源端口、目的端口)哈希将不同的数据流分配到不同的Rx队列,每个队列绑定不同的CPU核心处理,实现真正的多核并行接收处理。NTUPLE硬件过滤则允许在网卡硬件层面对特定的IP/端口/VLAN进行过滤,将无关流量直接丢弃,大幅减少CPU需要处理的数据包数量。
联瑞电子针对金融行业超低延迟场景提供完整的产品解决方案,覆盖行情接入、交易执行和结算清算各环节:
随着国家金融监管部门对金融基础设施国产化自主可控要求的持续强化,银行、证券、基金等金融机构的核心系统正在加速推进信创替代。在网络设备层面,金融信创对网卡的主要要求包括:
联瑞电子针对金融信创场景,推出了基于华为系国产以太网芯片的SP681和SP670网卡产品:
某股份制银行的股票交易系统改造项目(案例经匿名化处理):
改造背景:该银行自营交易部门的交易系统在高频行情推送时段出现明显延迟抖动,实测端到端延迟(从行情数据接收到订单发出)平均为850微秒,但P99延迟高达3.2毫秒,严重影响量化策略的执行质量。排查发现,原有系统使用普通千兆网卡+Linux内核协议栈方案,在行情高峰时段内核网络处理成为瓶颈。
改造方案:行情接收服务器升级为配置联瑞电子LRES1001PF-2SFP28(25G双口)网卡,部署DPDK+SPDK用户态驱动架构,将行情数据接收完全移至用户态处理;交易引擎主机同样配置25G网卡,禁用内核中断模式,改用DPDK PMD轮询模式;网络拓扑升级为全25G光纤直连,采用Cut-Through交换模式的低延迟交换机。
改造效果:升级完成后,端到端平均延迟从850微秒降至42微秒,降幅超过95%;P99延迟从3.2毫秒降至78微秒,延迟抖动大幅收敛。在随后的季报行情高峰测试中,系统稳定运行,未出现延迟尖刺,策略执行滑点较改造前降低了约67%。
在高频交易领域,降低物理距离带来的传播延迟与优化软件链路延迟同等重要。交易所托管服务(Co-location)与直连专线是顶级量化机构的标准配置。
交易所托管机房(沪深交易所Colocation)
上海证券交易所(上交所)和深圳证券交易所(深交所)均设有专属的托管服务区,允许持牌券商和量化机构将交易服务器托管在与交易所撮合引擎物理距离最近的机房内。以上交所外滩数据中心为例,托管服务器与撮合引擎之间的物理距离可缩短至数十米以内,专线物理延迟可控制在1~2微秒,相比普通互联网接入的数十毫秒延迟优势极为显著。中金所(期货交易所)同样提供类似的托管服务。托管Colocation的核心价值在于:距离最短→传播延迟最低、专用交叉连接→无公网拥塞风险、同机房内可实现低于1微秒的服务器间延迟。这三点共同构成高频交易策略"先于市场其他参与者感知并响应行情"的基础设施优势。
交叉连接(Cross-Connect)与直接市场访问(DMA)
托管机房内的交叉连接(Cross-Connect,XC)是指在同一数据中心内,通过专用光纤跳线将不同客户的机柜直接互连,或将客户服务器直连至交易所核心交换机,实现与DMA(直接市场访问)系统的最短路径连接。DMA允许买方机构(量化基金、自营机构)直接向交易所发送交易指令,绕过传统经纪商的中间层,将下单路径从"客户→经纪商→交易所"压缩为"客户→交易所"的两跳架构。在DMA环境下,25G专线的物理帧传输延迟(从网卡发出最后一个比特到对端收到第一个比特)在短距跳线场景下可低于100纳秒,整个下单链路(含OMS处理)可做到5~15微秒,是量化高频策略必须具备的基础条件。
联瑞25G网卡固件级延迟调优
在Colocation环境下,服务器与交易系统的延迟调优需要深入到固件(Firmware)和驱动层面。以联瑞电子LRES1001PF-2SFP28(基于Intel XXV710芯片)为例,在高频交易场景下需要进行以下关键调优:
FPGA加速交易方案简述
对于延迟要求达到亚微秒级别(<1µs)的超高频交易(Ultra-HFT),基于通用CPU的软件方案已接近物理极限。FPGA(现场可编程门阵列)方案通过在硬件逻辑中直接实现行情解析、策略计算和订单编码,将整个决策-下单流程的硬件延迟压缩至200~500纳秒。FPGA方案通常与标准25G网卡并行部署:网卡承担日常数据采集、系统管理和回测验证,FPGA专用硬件通道承担实时高频交易路径。联瑞电子的25G网卡(LRES1001PF-2SFP28)支持与主流FPGA交易加速卡(如Xilinx/AMD Alveo系列)的PCIe协同部署,在同一服务器中形成CPU+FPGA的混合交易加速架构。
在高频交易系统投产后,持续的网络延迟监控和快速故障诊断能力与初始部署同等重要。延迟的细微变化(甚至几十纳秒的增加)都可能影响策略执行质量,因此金融机构需要建立纳秒/微秒级的精细化监控体系。
纳秒级延迟监控工具
金融交易系统的延迟监控已从传统的毫秒级工具(如ping、traceroute)进化到专用的微秒/纳秒级工具链。常用方案包括:
PTP/IEEE 1588硬件时间戳与交易服务器微秒级时钟同步
金融交易系统中,所有服务器节点(行情服务器、交易引擎、风控服务器、结算服务器)都必须在统一的高精度时钟基准下工作,以确保跨节点的延迟测量准确有效,并满足监管机构对交易时间戳的合规要求。IEEE 1588-2008(PTP v2)精确时间协议提供了此类场景下的标准解决方案:
PTP的工作原理是在硬件层面捕获PTP消息的精确发送和接收时刻,通过Sync/Delay_Req/Delay_Resp报文交换计算出精确的时钟偏差(Offset)和传播延迟(Propagation Delay),由Slave时钟持续对自身时钟进行微调,最终将所有节点的时钟偏差控制在亚微秒级别。关键在于"硬件时间戳":传统软件时间戳在内核协议栈处理过程中因调度抖动可引入数十微秒的不确定误差;而支持硬件PTP的网卡(如联瑞电子LRES1001PF-2SFP28基于Intel XXV710)在PHY层面直接打上纳秒精度的时间戳,消除了软件路径的时序不确定性,使整个交易网络的时钟同步精度可稳定保持在±100纳秒以内。
网络抖动(Jitter)分析与根因定位
延迟抖动(Jitter)指的是延迟的波动范围,在高频交易中,P99延迟远比平均延迟更为关键——即使平均延迟仅有5µs,若P99延迟达到500µs,策略执行质量同样会受到严重影响。常见的延迟抖动来源及排查方法如下:
联瑞PTP硬件时间戳网卡在监控体系中的作用
联瑞电子LRES1001PF-2SFP28(Intel XXV710)和LREC9812BF-2SFP+(Intel X710)均内置支持IEEE 1588-2008的硬件PTP时间戳引擎,提供以下监控支撑能力:
研发中心地址:深圳市龙岗区龙城街道远洋新天地T10栋14楼
制造中心地址:深圳市龙岗区龙岗街道新生绿谷1B栋9-11楼
邮 箱: info@lr-link.com
技术支持: 19924451883


 产品咨询
产品咨询 技术支持
技术支持
 服务电话
服务电话服务热线:
4000-588-108