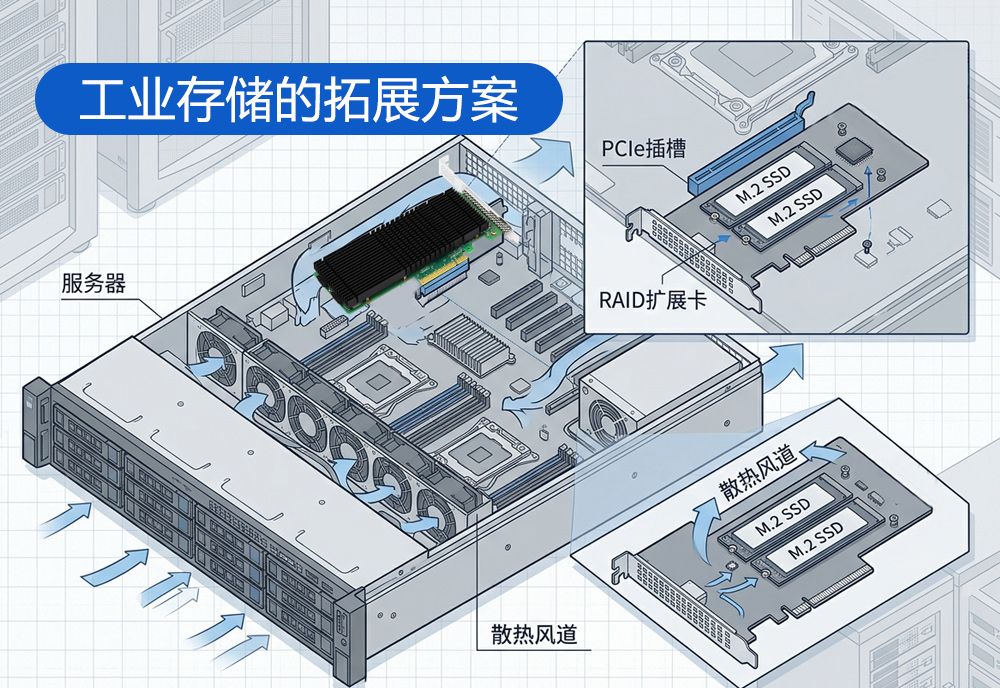
SERVER系列
PC系列



LR-LINK注重人才的自主培养,形成在内部竞聘和培养文化,并希望为员工提供最好的学习和持续发展的环境。也许,你是久经职场的精英;亦或,你是初出茅庐的菜鸟;不过没关系,只要你确实有料,同时有实现自我价值的激情,请留下你的简历,和我们一起锐意开拓,引领创新。


随着AI大模型训练规模突破万亿参数级别,以及下一代超大规模数据中心建设加速推进,2027年服务器网卡技术将迎来多个维度的重大演进。800G以太网标准落地、PCIe 6.0商用化、CXL 3.0内存共享生态成熟,以及AI SmartNIC(智能网卡)崛起,这四大趋势将深刻重塑数据中心网络架构。本文从技术路线图视角,前瞻性分析各趋势的技术内涵及对产品规划的影响。
当前400GbE正在大型数据中心和AI集群中快速铺开,而下一代800GbE标准(IEEE 802.3df)已于2024年初完成标准化,预计2026年底至2027年间开始在超大规模数据中心实现商用部署。800GbE标准有以下几个关键技术特征:
PCIe 6.0规范于2022年发布,相比PCIe 5.0(32GT/s),PCIe 6.0将速率提升至64GT/s,并引入PAM4(四级脉冲幅度调制)编码取代NRZ编码,x16插槽双向理论带宽高达256GB/s,较PCIe 5.0翻倍。
对于服务器网卡而言,PCIe 6.0的意义在于:单块400G/800G网卡终于不会受到PCIe总线带宽的制约。目前PCIe 5.0 x16理论峰值128GB/s,已能满足单口400G网卡(约50GB/s)的需求,但在双GPU服务器场景下,PCIe 6.0带宽翻倍将使AI训练的all-reduce通信延迟进一步降低。联瑞电子的LRES1260PF-2QSFP112(PCIe 5.0,双口400G RDMA)已是当前代际最高配置,PCIe 6.0版本产品规划紧随芯片厂商路线图推进。
CXL(Compute Express Link)是一种基于PCIe物理层的高速互联协议,旨在解决异构计算场景下的内存共享和一致性问题。CXL 3.0规范(基于PCIe 6.0物理层)在前两代基础上新增了多主机(Multi-Host)共享内存池特性,使多台服务器可以访问同一块共享内存池,延迟比通过网络传输数据降低约10倍。
CXL 3.0对AI推理场景尤具价值:大型LLM(如千亿参数GPT-4级别模型)推理时需要将模型权重全量加载到内存,单台服务器的DRAM容量(通常512GB~2TB)可能不足,而传统分布式内存方案延迟高。CXL 3.0内存语义网络允许多台服务器共享一个TB级内存池,延迟在微秒级,为超大规模推理提供了新的解决思路。预计2027年国内头部云厂商将率先在AI推理集群中部署CXL 3.0基础设施。
DPU(Data Processing Unit,数据处理器)是新一代智能网卡(SmartNIC)的演进形态,在传统网卡的网络包收发功能之外,内置了专用ARM/RISC-V多核处理器、硬件加速引擎和可编程数据面,能够将原本占用宿主机CPU的网络功能全部卸载到NIC上执行,主要包括:
| 产品 | 速率 | 处理器 |
|---|---|---|
| NVIDIA BlueField-3 | 400GbE | ARM A78 16核 |
| Marvell OCTEON 10 | 400GbE | ARM A72 36核 |
| Intel IPU E2100 | 200GbE | Intel Atom 16核 |
DPU卸载网络功能后,宿主机CPU可节省10%~30%的算力用于业务计算。2027年随着DPU成本下降和生态完善,预计将在千台以上规模的大型云数据中心大规模部署。对于中小型私有云,基于联瑞电子LRES1260PF-2QSFP112等高性能网卡配合DPDK的方案仍是主流性价比选择。
在国产替代政策驱动下,国内网卡芯片厂商近两年进展显著,呈现出技术代际快速追赶的态势:
联瑞电子作为国产网卡芯片的重要生态伙伴,已将沐创和华为Hi-Silicon芯片方案纳入产品线,并提供完整的信创认证支持。2027年随着国产25G/100G芯片大规模量产,性价比将进一步提升,国产网卡有望在政企和关键基础设施市场获得超过50%的份额。
面向2027年的技术趋势,企业IT团队在今年就应开始做好基础设施准备,避免届时大规模替换成本:
2027年服务器网卡技术演进呈现五大主线:①800GbE标准落地,②PCIe 6.0商用,③CXL 3.0内存共享成熟,④AI SmartNIC/DPU规模化,⑤国产芯片100G+跃升。这些趋势正在重塑数据中心基础设施架构,企业IT团队需要在今天的采购和规划决策中融入这些技术趋势的考量。联瑞电子将持续跟踪产业链最新进展,为客户提供覆盖当代最优和面向下一代的完整产品路线。
Q:800G网卡技术何时会普及到数据中心?
A:800G网卡技术的普及将呈现阶梯式推进规律,而非同步全面铺开。2026年底至2027年,800G网卡将率先在超大规模AI训练数据中心(Tier-1 CSP如AWS、Google、微软Azure及国内百度、阿里、腾讯等)实现小规模试商用部署,主要用于万卡级GPU集群的All-to-All通信互联;2028年前后,随着800G光模块成本降至合理区间(预计降至400G现行价格的1.5倍以内),800G将开始向金融、电信等高性能计算场景渗透。对于绝大多数企业级数据中心,400G将是2027年的性价比高点,而100G/25G仍是未来三年内企业私有云的主流配置选择,建议企业重点确保服务器支持PCIe 5.0插槽,为未来平滑升级预留物理条件。
Q:CXL 3.0对服务器网卡架构会带来什么变化?
A:CXL 3.0的"内存语义网络"特性将促使服务器网卡功能边界发生重要演进。传统网卡定位于I/O设备,负责数据包的收发;而在CXL 3.0架构下,具备CXL 3.0接口的SmartNIC可以同时承担内存语义传输功能,支持远端内存直接访问(Remote Memory Access),使跨服务器的内存操作延迟从RDMA的1~3μs进一步降低至亚微秒级。这意味着未来的高端智能网卡将是"网络+内存互联"双功能器件,集以太网/InfiniBand数据包处理与CXL内存语义传输于一身。从产品架构来看,2027年部分DPU(如NVIDIA BlueField下一代)已开始在路线图中纳入CXL 3.0支持,以满足AI推理集群的大规模内存共享需求,这将从根本上重塑数据中心计算与网络的融合边界。
Q:AI大模型训练对网卡带宽有什么要求?
A:AI大模型训练的网络带宽需求与模型参数量和并行策略密切相关。以千亿参数(100B+)模型为例,采用数据并行训练时,All-Reduce通信量约为2倍梯度大小,对于混合精度(FP16)的100B参数模型,单步通信量高达约400GB;采用流水线并行时,层间激活值传输对网络延迟更为敏感,要求节点间往返延迟(RTT)不超过5μs。综合来看,万卡级GPU训练集群的网络带宽需求为:单GPU节点至少配备400Gbps(双口200G或单口400G)的RDMA网卡,并要求网络支持RoCEv2或InfiniBand协议以实现内核旁路的低延迟通信。联瑞电子的LRES1260PF-2QSFP112(双口400G,PCIe 5.0,支持RoCEv2)是当前AI训练集群的最优规格选择,可充分满足万亿参数级模型训练的带宽与延迟需求。
Q:国产DPU芯片与国际产品差距几何?
A:从技术代际来看,国产DPU芯片目前与国际领先产品(NVIDIA BlueField-3、Marvell OCTEON 10)之间存在约2~3年的差距,但差距正在快速缩小。在网络速率方面,国产代表性DPU已达到100G级别,而BlueField-3已支持400GbE;在数据面处理能力方面,国产DPU的可编程数据面(P4/eBPF)成熟度和RDMA RoCEv2硬件卸载性能仍与国际产品有明显差距;在软件生态方面,国际产品的DPDK、OVS Offload、DOCA(NVIDIA)生态极为完善,国产DPU的开发工具链和参考实现相对薄弱。预计到2027年,随着国产28nm→12nm工艺升级和处理器算力提升,国产DPU有望在100G速率和企业级OVS卸载场景缩小至与国际产品1代以内的差距,成为信创DPU市场的有力竞争者。
Q:企业现在购买100G网卡是否会很快过时?
A:对于绝大多数企业来说,现在购买100G网卡不会"很快过时",仍是合理的投资决策。100GbE在2025~2027年仍处于企业高性能网络的主流带宽区间,充分满足分布式存储(Ceph/vSAN)、私有云高密度VM以及中等规模AI推理集群的带宽需求,网卡实际生命周期通常与服务器硬件绑定为5~8年,这一周期内100G对99%的企业应用场景绰绰有余。需要注意的是,应优先选择基于PCIe 4.0或PCIe 5.0接口的100G网卡,确保与下一代服务器平台的兼容性;同时建议选择支持RDMA的型号(如联瑞电子LRES1250PF-2QSFP56 100G/200G RDMA网卡),为未来高性能存储网络和AI推理业务留好扩展能力,避免因协议能力不足而导致提前换卡,让每一笔采购投资都发挥最大价值。
研发中心地址:深圳市龙岗区龙城街道远洋新天地T10栋14楼
制造中心地址:深圳市龙岗区龙岗街道新生绿谷1B栋9-11楼
邮 箱: info@lr-link.com
技术支持: 19924451883


 产品咨询
产品咨询 技术支持
技术支持
 服务电话
服务电话服务热线:
4000-588-108