SERVER系列
PC系列



LR-LINK注重人才的自主培养,形成在内部竞聘和培养文化,并希望为员工提供最好的学习和持续发展的环境。也许,你是久经职场的精英;亦或,你是初出茅庐的菜鸟;不过没关系,只要你确实有料,同时有实现自我价值的激情,请留下你的简历,和我们一起锐意开拓,引领创新。


如果你在网络行业待过一段时间,大概率听过这样的说法:"RDMA是超算和金融行业才用得起的东西,普通数据中心根本用不上。"
这句话在五年前或许有一定道理。但放到今天,它已经成为网络基础设施领域较大的误解之一。随着云计算、分布式存储和人工智能训练任务的增长,RDMA早已走出了实验室,成为越来越多企业数据中心里的标配能力。
这个误解的形成并非没有原因。
早期的RDMA确实很"贵"。 最初的RDMA主要依赖InfiniBand网络,需要专用交换机和配套设备,整套方案的价格让大多数企业望而却步。只有少数大型超算中心和对延迟非常敏感的交易系统才会使用。
技术门槛确实存在。 RDMA涉及内核旁路、零拷贝传输、硬件卸载等一系列底层概念,对于没有系统学习过高性能网络的管理员来说,理解起来确实有一定难度。很多技术文章一上来就堆砌术语,让人望而生畏。
生态曾经是封闭的。 早年间支持RDMA的硬件和软件生态较为有限,普通操作系统和应用程序很难直接利用这项技术,这进一步加深了"这东西跟我没关系"的印象。
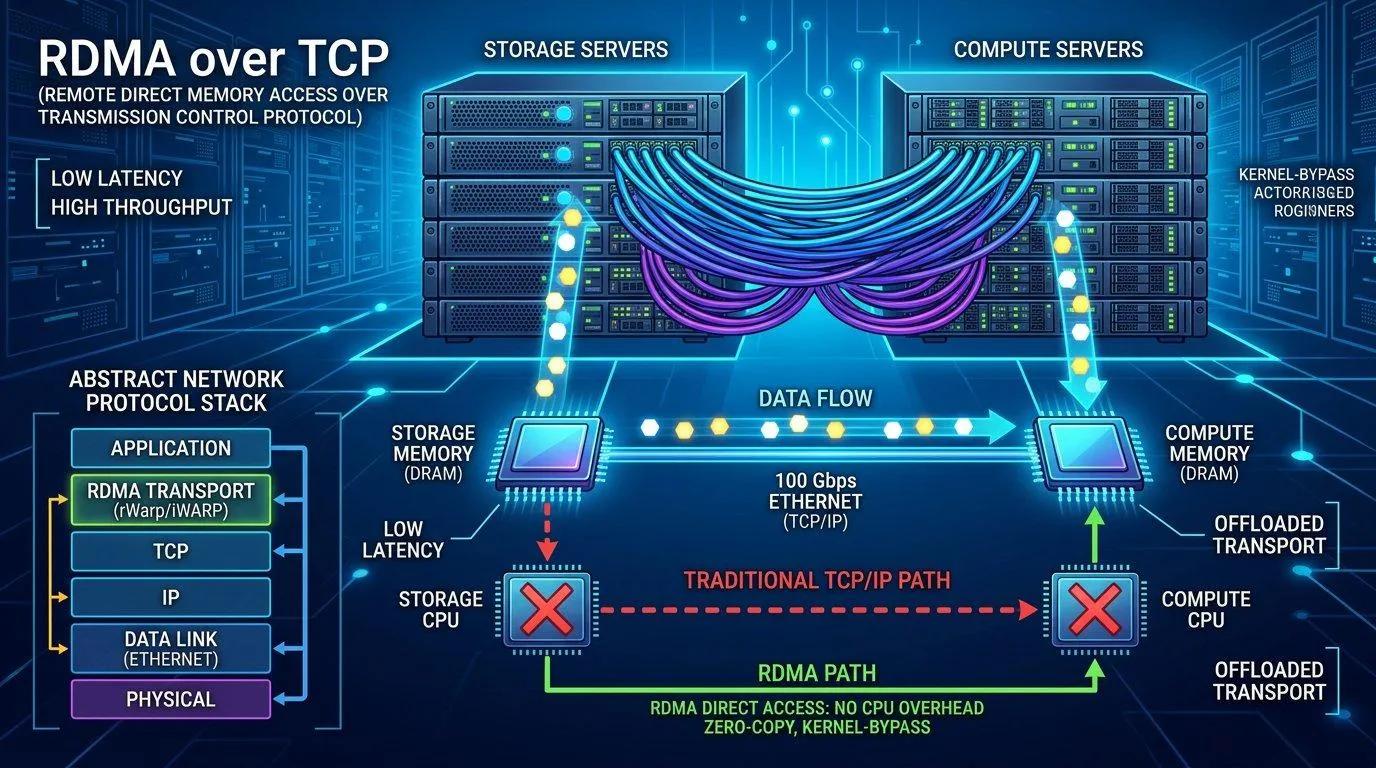
抛开所有术语,RDMA的全称是"Remote Direct Memory Access",翻译成中文就是"远程直接内存访问"。
打个比方。想象你在办公室里需要把一份文件从隔壁同事的桌上拿过来。传统的网络传输方式就像你打电话给同事,让同事把文件拍照发给你,你再打印出来——中间经过了很多步骤,每多一步就多一分延迟和开销。而RDMA相当于你直接走到同事桌前,自己动手把文件拿回来,全程不需要同事帮忙。
用技术语言来说,RDMA允许一台服务器的网卡直接读写另一台服务器的内存,完全绕过双方的CPU和操作系统内核。这就是所谓的"内核旁路"和"零拷贝"。
传统网络通信需要经过多层协议栈处理,每次都要CPU介入,延迟通常在数十微秒级别。RDMA通过硬件直接处理数据传输,端到端延迟可以降到一微秒左右,提升幅度达到数十倍。
在传统的TCP/IP网络中,网络数据传输会大量消耗CPU资源。使用RDMA后,数据传输由网卡硬件直接完成,CPU可以被释放出来处理业务逻辑。对于数据库、分布式存储这类CPU敏感型应用来说,这个优势非常明显。
RDMA天然支持高带宽场景。配合100G甚至更高带宽的网络适配器,单链路吞吐可以达到100Gbps以上,轻松应对大规模数据迁移、AI模型训练等高吞吐需求。
如果说InfiniBand时代的RDMA还是"阳春白雪",那么RoCE(RDMA over Converged Ethernet)的出现则彻底改变了格局。
RoCE技术的核心思路很简单——把RDMA的能力直接"搬到"标准以太网上运行。这意味着你不需要推倒现有的以太网基础设施,不需要购买专用交换机,只要在服务器端换上支持RDMA的智能网卡,就能享受到低延迟、低CPU占用的数据传输能力。
目前主流的RoCEv2协议已经非常成熟,被广泛应用于云存储、虚拟化、容器网络和人工智能集群等场景。国内外主流云服务商已在内部大规模使用RoCE网络。
要使用RDMA,你需要一块支持该功能的智能网卡。联瑞电子(LR-LINK)提供了多款支持RDMA/RoCE能力的网络适配器,覆盖从25G到100G的不同场景需求。
25G场景。 LRES1001PF-2SFP28是一款PCIe x8双光口25G SFP28以太网适配器,适合虚拟化服务器和中等规模存储集群的接入。
100G PCIe场景。 LRES1014PF-2QSFP28是一款PCIe x16双光口100G QSFP28以太网适配器,基于Intel E810主控,支持多速率(10/25/50/100Gbps),适合高性能计算节点和AI训练服务器的互联。
100G QSFP56场景。 LRES1080PF-2QSFP56是一款PCIe x16双口100G QSFP56以太网适配器,支持RoCEv2和NVMe-oF协议,可配置为2x100G、1x200G、4x50G等多种速率模式,适合AI/ML、数据中心和高性能计算场景。
并非所有场景都需要RDMA。以下几个判断标准可以帮助你决定是否需要引入这项技术。
你的应用对延迟敏感吗。 如果你的业务涉及实时数据库、分布式锁等对网络延迟非常敏感的场景,RDMA带来的微秒级延迟优势非常有价值。
你的网络是否成为瓶颈。 当服务器CPU大量时间花在处理网络数据包而非执行业务逻辑时,RDMA的内核旁路机制可以有效释放CPU资源。
你在做大规模数据搬运吗。 AI训练中的模型参数同步、分布式存储的数据复制、大规模虚拟机迁移,这些场景下RDMA的高吞吐和低开销优势非常明显。
你的带宽达到25G以上了吗。 当网络带宽从10G升级到25G甚至100G时,传统TCP/IP协议栈的CPU开销会急剧增加,RDMA的价值也更加凸显。
RDMA是一种网络协议层面的能力,需要网卡硬件支持,它从协议层面实现了内核旁路和零拷贝。DPDK是一种软件框架,通过用户态驱动和轮询机制来加速数据包处理,仍然需要CPU参与。两者可以互补,但RDMA的硬件卸载效率通常更高。
取决于你选择的RDMA编程接口。使用"verbs"接口需要对应用进行专门适配。但如果使用iWARP或通过NVMe-oF、SMB Direct等已经支持RDMA的上层协议,应用程序可能不需要做任何修改,底层的存储或文件服务协议会自动利用RDMA加速。
RoCEv2在标准以太网上运行,但为了获得良好效果,建议交换机支持PFC(基于优先级的流量控制)和ECN(显式拥塞通知)等无损网络特性。普通的非管理型交换机虽然也能传输RoCE流量,但可能在高负载时出现丢包,影响RDMA性能。
不一定。RDMA是一项需要网卡芯片专门设计支持的功能,并非所有高速网卡都具备。在选购时,需要确认网卡明确标注支持RDMA或RoCEv2。联瑞电子的多款25G和100G适配器均已支持该功能。
由于RDMA绕过了操作系统内核,传统的基于内核的网络防火墙和访问控制机制无法直接拦截RDMA流量。在生产环境中,可以通过网络隔离(VLAN/VRF)、加密传输(如IPsec)以及物理层面的安全策略来保障RDMA通信的安全性。
联系LR-LINK技术团队获取免费选型咨询
研发中心地址:深圳市龙岗区龙城街道远洋新天地T10栋14楼
制造中心地址:深圳市龙岗区龙岗街道新生绿谷1B栋9-11楼
邮 箱: info@lr-link.com
技术支持: 19924451883


 产品咨询
产品咨询 技术支持
技术支持
 服务电话
服务电话服务热线:
4000-588-108