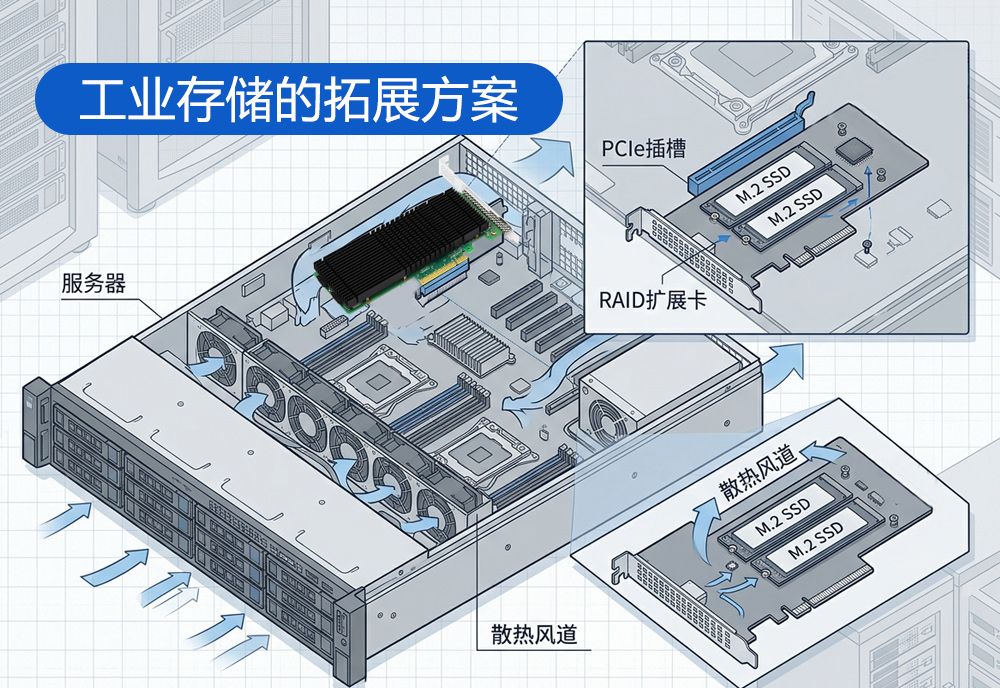
SERVER系列
PC系列



LR-LINK注重人才的自主培养,形成在内部竞聘和培养文化,并希望为员工提供最好的学习和持续发展的环境。也许,你是久经职场的精英;亦或,你是初出茅庐的菜鸟;不过没关系,只要你确实有料,同时有实现自我价值的激情,请留下你的简历,和我们一起锐意开拓,引领创新。


RDMA(Remote Direct Memory Access,远程直接内存访问)是一种高性能网络通信技术,允许网络中的一台计算机直接读写远端计算机的内存数据,整个过程无需CPU介入,也不经过操作系统内核协议栈。这种"零拷贝、内核旁路"的数据传输方式,能够实现微秒级的端到端延迟和接近线速的吞吐量,是当前高性能计算(HPC)和AI训练集群的核心网络技术。
RDMA技术的诞生源于传统TCP/IP网络协议栈的固有瓶颈。在传统网络通信中,一次数据传输需要经历多次内存拷贝(用户态到内核态、内核态到网卡缓冲区),同时伴随频繁的CPU中断和上下文切换。当网络带宽从10G跃升到100G乃至400G时,CPU处理协议栈的开销已经成为严重瓶颈——大量计算资源被消耗在数据搬运上,而非业务计算本身。
RDMA技术的核心价值体现在三个方面:
目前业界主流的RDMA实现方式有三种:InfiniBand、iWARP和RoCE(RDMA over Converged Ethernet)。三者在底层网络、性能表现、成本和部署难度上各有差异。
InfiniBand是最早实现RDMA的专用网络架构,拥有独立的链路层、网络层和传输层协议。它在延迟和吞吐方面表现最优,是HPC领域的传统首选,但需要专用的InfiniBand交换机和线缆,整体建设成本和运维复杂度较高。
iWARP(Internet Wide Area RDMA Protocol)将RDMA语义封装在TCP/IP协议之上,因此可以运行在任何标准以太网基础设施上,兼容性最好。但由于底层依赖TCP协议,在延迟和吞吐性能上相比InfiniBand和RoCEv2有明显差距,目前在大规模部署中较少使用。
RoCE/RoCEv2是将RDMA协议直接承载在以太网上的方案。RoCE v1基于链路层(L2)以太网帧封装,不支持IP路由,部署受限于同一二层网络。RoCEv2(也称RRoCE)在此基础上引入UDP/IP封装,支持L3路由转发,大幅扩展了适用范围,已成为当前数据中心和AI集群中最主流的RDMA部署方案。
在大规模AI训练集群的网络选型中,RoCEv2已经成为事实上的主流方案,其核心优势在于以下几点:
复用现有以太网基础设施。绝大多数数据中心已经部署了成熟的以太网交换和布线体系。采用RoCEv2方案意味着企业无需另建一套InfiniBand专用网络,可以在现有以太网架构上直接升级部署RDMA能力,显著降低初期投资和后续运维成本。
支持L3路由,适合大规模数据中心。RoCEv2基于UDP/IP封装,天然支持三层路由转发。这意味着RDMA流量可以跨越不同子网和机房进行传输,非常适合拥有数千甚至上万节点的大规模AI训练集群。相比之下,RoCE v1仅限于二层网络域内通信,扩展性受限。
配合PFC和ECN实现无损以太网。RDMA对丢包极为敏感,即使极低的丢包率也会导致性能急剧下降。RoCEv2通过配合数据中心桥接技术(DCB)中的PFC(Priority-based Flow Control,基于优先级的流量控制)和ECN(Explicit Congestion Notification,显式拥塞通知)机制,可以在标准以太网上构建"无损网络",确保RDMA数据包的可靠传输。目前主流数据中心交换机均已支持这些特性。
在现代大规模AI模型训练中,RDMA网卡扮演着至关重要的角色。以大语言模型(LLM)训练为例,一次训练任务通常需要数百甚至数千张GPU协同工作,GPU之间的通信效率直接决定了整体训练速度和资源利用率。
GPU集群中的参数同步。在数据并行训练中,每张GPU独立计算梯度后需要通过AllReduce操作将所有梯度汇聚并同步。当集群规模达到千卡级别时,每轮迭代的梯度同步数据量可达数十GB。使用RDMA网卡可以将这一过程的通信延迟从毫秒级降低到微秒级,同时释放GPU所在主机的CPU资源。
模型并行与数据并行中的通信开销。对于参数量超过千亿的超大模型,单张GPU无法容纳完整模型,必须采用张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)。这些并行策略要求GPU之间频繁交换中间激活值和梯度数据,对网络带宽和延迟提出了极高要求。RDMA网卡的零拷贝和内核旁路能力,使得节点间通信的开销降到最低,从而最大化GPU计算效率。
联瑞电子400G RDMA网卡的应用。联瑞电子推出的LRES1260PF-2QSFP112 400G RDMA网卡,专为AI训练和高性能计算场景设计。该网卡采用双端口QSFP112接口,总带宽达400Gbps,搭载PCIe 5.0 x16高速总线接口,全面支持RoCEv2协议。在大规模GPU集群中,该网卡可为每个计算节点提供充足的网络带宽,有效消除参数同步和数据交换中的网络瓶颈,适用于大语言模型训练、推荐系统训练、科学计算等高性能场景。
在选购RDMA网卡时,需要从以下几个维度进行评估:
带宽需求评估。根据集群规模和业务负载确定所需带宽等级。小规模集群(数十节点)可选择100G网卡;中等规模集群(数百节点)建议采用200G网卡;大规模AI训练集群(千卡以上)推荐400G网卡以确保充足的通信带宽。
芯片方案选择。RDMA网卡的核心在于网络控制器芯片。不同芯片方案在功能特性、驱动成熟度和生态兼容性上存在差异。选型时应关注芯片对RoCEv2的支持完整度、硬件卸载能力(如校验和卸载、大段卸载等)以及与主流NCCL/MPI通信库的兼容性。
PCIe代次与插槽兼容。网卡的PCIe接口代次直接影响主机端的数据吞吐上限。400G网卡通常需要PCIe 5.0 x16插槽才能充分发挥性能;100G网卡可在PCIe 4.0 x16或PCIe 3.0 x16下运行。选型前需确认服务器主板的PCIe插槽规格。
联瑞电子RDMA网卡推荐型号:
Q: RDMA需要特殊的交换机吗?
A: 取决于所选的RDMA实现方式。InfiniBand需要专用的InfiniBand交换机。RoCEv2可以运行在标准以太网交换机上,但要获得最佳性能,交换机需要支持数据中心桥接(DCB)特性,包括PFC(基于优先级的流量控制)和ECN(显式拥塞通知),以构建无损以太网环境。目前主流数据中心级交换机(如各大厂商的25G/100G/400G交换机)均已支持这些特性。
Q: RoCEv2和RoCE v1有什么区别?
A: 两者最核心的区别在于网络层封装。RoCE v1直接在以太网链路层(L2)帧上承载RDMA报文,不具备IP封装,因此只能在同一二层广播域内通信,不支持跨子网路由。RoCEv2在RoCE v1的基础上增加了UDP/IP封装头,使RDMA报文可以像普通IP数据包一样进行三层路由转发,适合大规模跨子网的数据中心部署。此外,RoCEv2还能利用基于UDP源端口的ECMP负载均衡,进一步优化多路径网络中的流量分布。
Q: RDMA网卡驱动怎么安装?
A: RDMA网卡的驱动安装一般分为以下步骤:首先,确认操作系统版本并下载对应的网卡驱动程序和RDMA用户态库(如libibverbs、librdmacm等)。在Linux系统中,推荐安装网卡厂商提供的OFED(OpenFabrics Enterprise Distribution)驱动包,它包含了内核驱动、用户态库和管理工具的完整套件。安装完成后,通过ibstat或rdma link命令验证RDMA设备是否识别正常,再使用ib_write_bw或perftest工具进行带宽和延迟测试。具体安装步骤请参阅联瑞电子官网的产品技术文档和驱动下载页面。
研发中心地址:深圳市龙岗区龙城街道远洋新天地T10栋14楼
制造中心地址:深圳市龙岗区龙岗街道新生绿谷1B栋9-11楼
邮 箱: info@lr-link.com
技术支持: 19924451883


 产品咨询
产品咨询 技术支持
技术支持
 服务电话
服务电话服务热线:
4000-588-108