技术详解
什么是iWARP?RDMA三大传输协议深度对比:iWARP vs RoCEv2 vs InfiniBand
导读
RDMA(Remote Direct Memory Access,远程直接内存访问)技术通过绕过操作系统内核,实现跨节点的内存直接读写,显著降低通信延迟、减少CPU占用。当前RDMA有三种实现方式:InfiniBand、RoCE(基于以太网)和iWARP(基于TCP/IP)。其中iWARP 常被忽视,但其"天然适配有损以太网"的特性在特定场景下具有独特价值。本文系统梳理三种协议的技术原理与差异,帮助您在AI训练、存储互联、分布式计算等场景中做出正确的RDMA网卡选型决策。
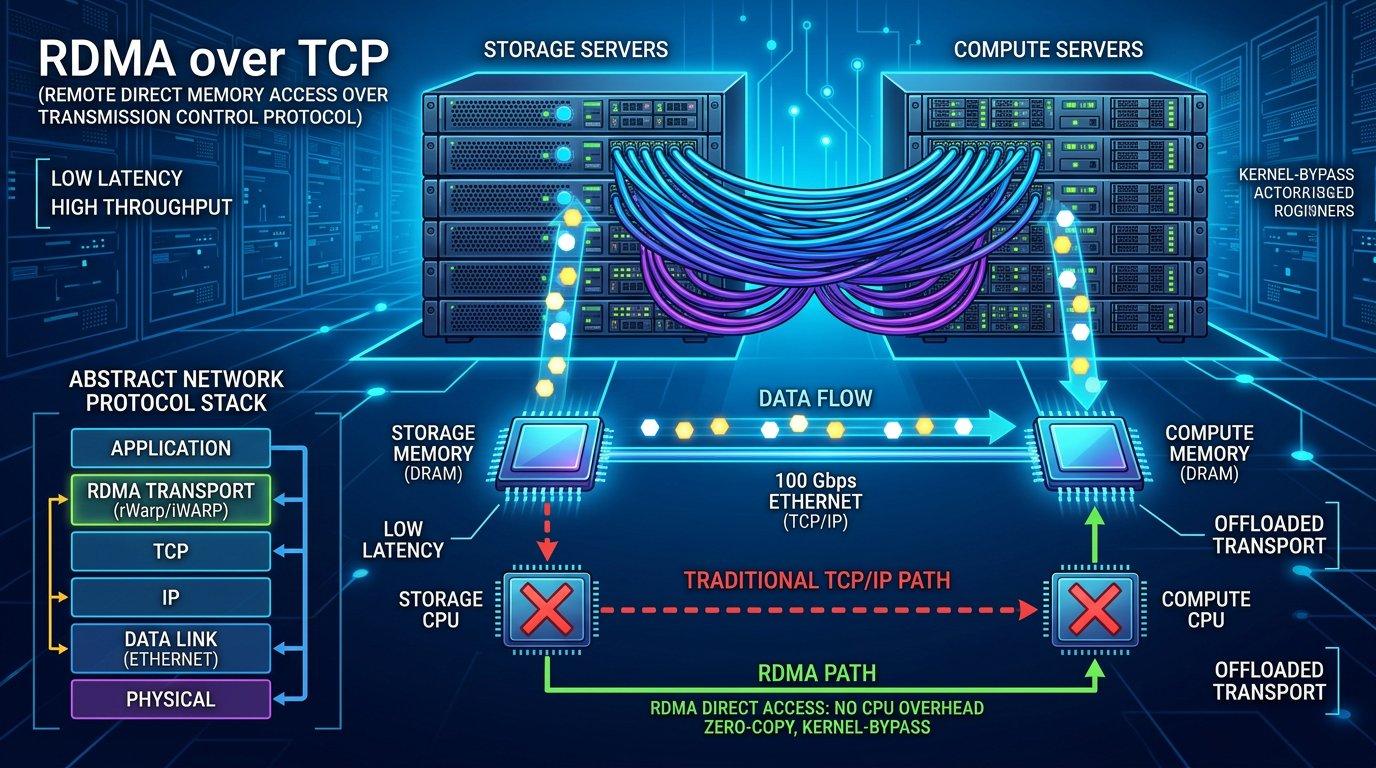
RDMA的核心价值在于:发送方可以直接将数据写入接收方的内存缓冲区,无需接收方CPU参与,从而实现微秒级延迟和接近零CPU占用的高性能通信。然而,"RDMA"并非一个单一技术标准,而是一个能力描述,其具体实现在传输层存在三条技术路线:
InfiniBand(IB) :由IBTA组织制定的专有高速互联技术,从物理层到传输层均为独立标准,与以太网完全隔离。InfiniBand提供无损网络保障(基于基于信用的流控),延迟最低,通常在AI超算集群中作为首选,但需要专用交换机(如NVIDIA Quantum系列),部署成本最高。
RoCE(RDMA over Converged Ethernet) :将RDMA语义运行在以太网之上的技术标准,分为RoCEv1(基于以太帧,不可路由)和RoCEv2(基于UDP/IP,可路由)。RoCEv2复用标准以太网交换机基础设施,但需要配置PFC(优先级流控)和ECN(显式拥塞通知)来构建无损以太网,是目前AI训练集群的主流选择。
iWARP(Internet Wide Area RDMA Protocol) :将RDMA语义运行在标准TCP/IP协议栈之上的技术,由IETF制定。由于TCP本身已提供可靠、有序的数据传输,iWARP天然支持在有损以太网(甚至广域网WAN)上运行,无需PFC等特殊网络配置,但TCP协议的开销也带来了相比InfiniBand和RoCEv2更高的延迟和CPU负载。iWARP的实现依赖于硬件TCP卸载引擎(TOE,TCP Offload Engine),必须通过专用RDMA网卡(如早期Chelsio T-Series、Marvel FastLinQ系列)实现。
▲ 支持RDMA的高速网络适配器
iWARP协议栈由三层协议叠加构成,每一层均有明确的IETF RFC定义:
RDMAP(RFC 5040) :RDMA协议层,定义RDMA语义(Send/Recv, Read, Write操作)及其与下层协议的接口。
DDP(Direct Data Placement,RFC 5041) :直接数据放置层,负责将数据直接放置到内存目标地址,避免数据拷贝。DDP基于MPA分片进行传输,每个DDP Segment对应一个MPA帧。
MPA(Marker PDU Alignment,RFC 5044) :标记PDU对齐层,运行于TCP之上,负责将DDP分段封装为可通过TCP字节流传输的帧,并通过Marker机制实现在TCP重传恢复后的边界对齐。
iWARP的关键实现挑战在于硬件TCP卸载引擎(TOE) 。由于iWARP需要在硬件中实现完整的TCP/IP协议栈处理(包括三次握手、重传、流控、拥塞控制等),以避免CPU参与TCP处理导致延迟增加,这要求网卡芯片内置专用的TOE硬件单元。TOE的实现复杂度远高于RoCEv2的UDP卸载,这也是iWARP网卡种类相对较少、成本较高的根本原因之一。
从延迟角度看,iWARP的硬件TOE实现可以将单向延迟控制在2~5μs(微秒)范围内,虽高于InfiniBand的<1μs和RoCEv2的1~2μs,但在数据中心WAN场景(延迟本身就在毫秒级)中,这一差异可以忽略不计。
对比维度
InfiniBand
RoCEv2
iWARP
底层传输协议
IB 专有协议
UDP/IP/Ethernet
TCP/IP/Ethernet
典型单向延迟
<1 μs
1~2 μs
2~5 μs
最大吞吐(单卡)
400Gbps (NDR)
400Gbps
25/100Gbps
无损网络要求
内置,信用流控
需配置PFC+ECN
无需(TCP自带)
交换机要求
专用IB交换机
支持PFC/ECN的以太网交换机
标准以太网交换机
广域网(WAN)支持
不支持
有限支持
原生支持
部署复杂度
高(独立网络)
中(需无损配置)
低(标准IP网络)
成本
高
中
中
典型场景
AI超算集群、HPC
AI训练/推理、NVMe-oF、存储
WAN RDMA、异构存储网络
RDMA 三大传输协议栈对比
InfiniBand
RoCEv2
iWARP
应用层 RDMA Verbs API(共同接口)
RDMA Transport (IB RC/UC/UD)
InfiniBand Network Layer
InfiniBand Link Layer
IB Physical (专用光/铜缆)
RDMA Transport (RC/UC/UD)
UDP / IP(GRH over UDP)
Ethernet (需 PFC + ECN)
标准以太网光/铜缆
RDMAP(RFC 5040)
DDP(RFC 5041)
MPA / TCP(硬件TOE卸载)
标准以太网 (有损/无损均可)
专用物理网络
延迟最低,成本最高
需无损以太网(PFC+ECN)
主流AI训练方案
标准IP网络,无需特殊配置
天然支持有损网络 / WAN
▲ RDMA三种实现方式协议栈层次对比(iWARP基于TCP,原生兼容有损网络)
核心优势:
天然支持有损以太网: TCP本身具备可靠传输机制,丢包时由硬件TOE自动重传,无需部署PFC(优先级流控)。这意味着iWARP可以在未经特殊配置的标准以太网交换机上直接运行RDMA业务,大幅简化网络运维。
广域网(WAN)RDMA能力: 由于基于标准TCP/IP,iWARP数据可以跨路由器、跨数据中心传输,是目前唯一能够在WAN上实现RDMA语义的主流方案。对于需要跨园区或跨数据中心存储复制的场景,iWARP具有独特价值。
与现有IP基础设施完全兼容: 无需升级交换机固件,无需配置PFC域,运维人员无需掌握RDMA网络运维技能,降低了IT团队的学习成本。
防火墙穿透能力: 基于TCP端口的流量可以通过防火墙和NAT设备,这是基于UDP的RoCEv2所无法实现的。
主要劣势:
延迟高于RoCEv2: TCP的三次握手、ACK机制和拥塞控制算法引入了额外的延迟开销,在同等硬件条件下,iWARP的单向延迟通常比RoCEv2高50%~200%。对于延迟敏感的AI训练AllReduce操作,这一差异会显著影响训练速度。
芯片实现复杂,产品选择少: 硬件TOE的实现复杂度使支持iWARP的网卡产品种类有限,主要集中在低速端口(25G/100G),400G iWARP产品极为稀少,限制了其在高性能计算场景的应用。
连接建立开销大: 每个iWARP RDMA连接需要先建立TCP连接,在大规模集群(如数千节点的AI集群)中,节点间的All-to-All连接建立需要消耗大量资源。
随着大规模AI训练集群(数百至数千GPU节点)的兴起,RDMA的性能需求被推向极限,RoCEv2凭借以下优势成为当前业界首选:
更低延迟满足AllReduce要求: 分布式训练的AllReduce集合通信对延迟极为敏感,RoCEv2 1~2μs的延迟使千卡集群的同步效率显著优于iWARP。
PFC+ECN技术成熟: 主流数据中心交换机(Cisco Nexus、Arista、华为CloudEngine等)均支持PFC和ECN配置,无损以太网的部署已相当成熟,运维体系完善。
Mellanox/NVIDIA生态主导: ConnectX系列网卡(CX5/CX6/CX7)对RoCEv2的支持极为完善,配合NVIDIA UFM网络管理软件,提供了一套完整的AI集群网络解决方案。
成本优势: 复用标准以太网基础设施,相比InfiniBand节省专用交换机成本30%~50%。
▲ 基于RoCEv2的大规模AI训练集群网络
尽管RoCEv2在AI训练场景中占据主导,但iWARP在以下特定场景中仍有不可替代的价值:
跨数据中心或WAN的RDMA存储复制: 当两个数据中心之间需要通过RDMA协议同步复制NVMe-oF存储数据,且WAN链路不支持PFC时,iWARP是唯一可用的RDMA方案。典型应用包括金融双活数据中心的数据同步。
无法改造现有网络基础设施的环境: 部分企业的遗留网络交换机不支持PFC配置,或网络运维团队无力进行无损以太网配置,此时iWARP可以在不改造网络的前提下获得RDMA加速能力。
存储网络(iSER/NVMe-oF over iWARP): 对于不要求最低延迟,但希望降低CPU开销的NVMe-oF存储访问场景,iWARP提供了在标准IP网络上运行NVMe-oF的能力。
云原生和容器化RDMA场景: 在Kubernetes/OpenStack混合云环境中,东西向流量跨越多个网络域,PFC的无损保障难以在整个路径上维持,iWARP的TCP传输优势更加凸显。
联瑞电子提供完整的RDMA网卡产品线,覆盖25G至400G各速率段,全部支持RoCEv2 RDMA:
25G RoCEv2
接口: PCIe 4.0 x8
端口: 双口 SFP28 25G
芯片: Intel E810
RDMA: RoCEv2 / DPDK
适用场景:存储集群、小规模AI推理、NVMe-oF
100G RoCEv2
接口: PCIe 4.0 x16
端口: 双口 QSFP28 100G
芯片: Intel E810
RDMA: RoCEv2 / SR-IOV / DPDK
适用场景:AI推理集群互联、分布式存储NVMe-oF
400G RoCEv2
接口: PCIe 5.0 x16
端口: 双口 QSFP112 (2×200G)
芯片: 高性能RDMA控制器
RDMA: RoCEv2 / RDMA over PCIe / DPDK
适用场景:大规模AI训练集群、GPU超算节点互联
Q:我的网络交换机不支持PFC,能否使用RoCEv2?
A:在没有PFC的有损网络中使用RoCEv2会遇到丢包触发严重性能下降(称为"RDMA性能悬崖"),通常不推荐。此时有两个选择:一是升级交换机并配置PFC+ECN构建无损以太网;二是改用iWARP,天然兼容有损网络,无需任何交换机配置变更。
Q:同一台服务器能否同时使用RoCEv2和iWARP?
A:可以。RoCEv2和iWARP网卡可以同时安装在同一台服务器上,通过不同的网口分别处理局域网内的高性能训练流量(RoCEv2)和跨数据中心的存储复制流量(iWARP)。上层RDMA应用通过标准RDMA Verbs API访问,通过rdma_cm选择不同的设备。
Q:联瑞电子的RoCEv2网卡是否支持NVMe-oF协议?
A:是的。LRES1021PF-2SFP28、LRES1014PF-2QSFP28和LRES1260PF-2QSFP112均支持NVMe-oF over RoCEv2(NVMe/RDMA)协议,Linux内核4.9+已原生支持NVMe-oF initiator,配合nvme-cli工具可快速挂载远端NVMe存储,实现微秒级存储访问延迟。
需要专业选型建议?
联瑞电子技术团队提供一对一选型咨询,助您找到最优方案
立即咨询 →









 产品咨询
产品咨询

 服务电话
服务电话