SERVER系列
PC系列



LR-LINK注重人才的自主培养,形成在内部竞聘和培养文化,并希望为员工提供最好的学习和持续发展的环境。也许,你是久经职场的精英;亦或,你是初出茅庐的菜鸟;不过没关系,只要你确实有料,同时有实现自我价值的激情,请留下你的简历,和我们一起锐意开拓,引领创新。


随着大语言模型(LLM)、生成式AI和科学计算的快速发展,AI训练与推理对底层基础设施的要求已远超传统数据中心的设计能力。GPU集群规模从百卡扩展到万卡级别,节点间通信带宽需求从25G飙升至400G,而PCIe总线、内存容量、信号完整性等环节同时面临巨大压力。联瑞电子(LR-LINK)针对AI与高性能计算场景,提供覆盖高速网络互联、GPU扩展、信号保障、内存扩展四大核心环节的全栈配件方案,帮助客户构建高效、稳定、可扩展的AI计算基础设施。
当前AI与HPC基础设施的建设面临四大核心瓶颈,任何一个环节成为短板,都将导致整体计算效率的大幅下降:
大模型训练依赖数据并行和模型并行策略,每轮迭代需要在数百甚至数千张GPU之间同步海量梯度数据。传统TCP/IP网络的高延迟和CPU开销使得通信时间占比超过30%,严重拖慢训练进度,GPU利用率不足60%。
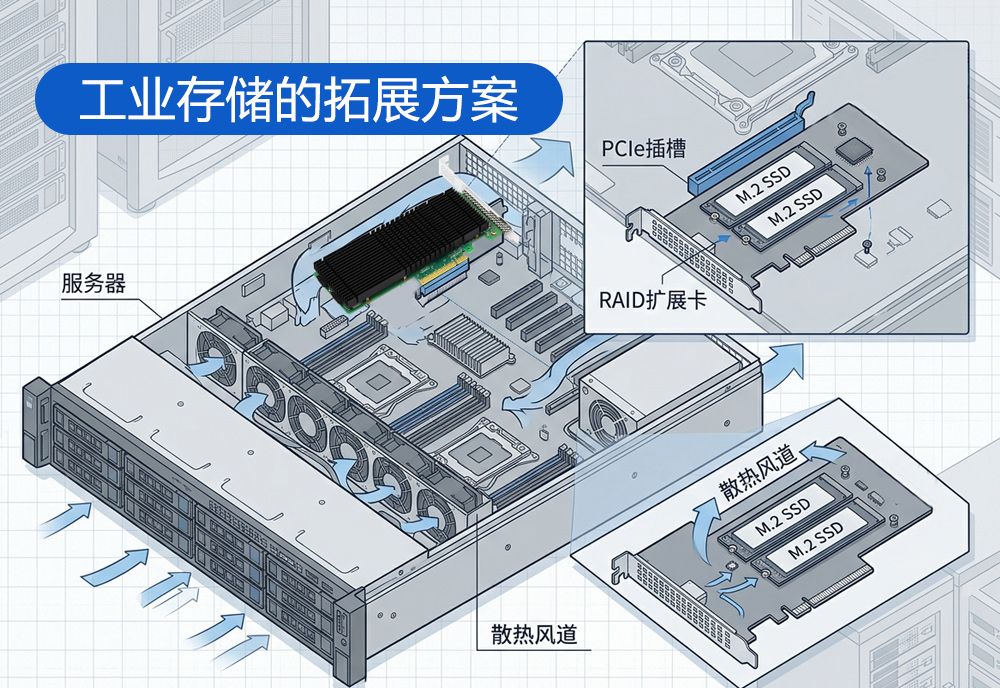
标准2U/4U服务器的PCIe插槽数量有限,难以同时安装多张GPU、网卡和NVMe存储设备。当GPU数量需要从8卡扩展到16卡乃至更多时,物理插槽成为硬性瓶颈,传统方案只能通过增加服务器数量来解决,导致成本和管理复杂度同步攀升。
TCP/IP协议栈的多次内存拷贝和内核中断处理,在100G以上速率下产生显著的CPU开销。AllReduce等集合通信操作对尾延迟极为敏感,即使少量丢包也会导致整体训练步骤的等待时间成倍增长。
千亿参数级别的大语言模型在推理时需要将完整模型权重加载到内存中。单台服务器的DDR5内存容量(通常512GB-2TB)难以承载超大模型,而传统的模型切片方案引入额外通信开销,增加了推理延迟。
联瑞电子围绕AI服务器和HPC集群的实际需求,构建了由前端网络、GPU扩展、信号保障、内存扩展四大模块组成的完整解决方案。各模块协同配合,从网络互联到内部总线,全面消除性能瓶颈。
在AI训练集群中,节点间的参数同步和梯度交换需要超高带宽和超低延迟的网络支撑。联瑞电子提供从100G到400G的全速率RDMA网卡,支持RoCEv2协议,实现零拷贝、内核旁路的数据传输。GPU到GPU的通信延迟降低至2微秒以内,有效吞吐接近物理链路线速,配合PFC和ECN机制构建无损以太网,确保集合通信操作的稳定性和一致性。在千卡级训练集群中,采用400G RDMA网卡可将GPU利用率从60%提升至85%以上。
PCIe Switch扩展卡通过在单个PCIe根端口下扇出多个下游端口,实现GPU、NVMe SSD等高速设备的灵活扩展。联瑞电子的PCIe 5.0 Switch扩展卡支持将1个x16上行端口扩展为2-4个下游端口,每个端口均保持PCIe 5.0的全速带宽。这意味着在不增加服务器数量的前提下,可以在单台服务器内接入更多GPU或NVMe存储设备。该方案还支持Non-Transparent Bridge(NTB)模式,实现多主机间的高速点对点数据传输,适用于GPU资源池化和分布式存储加速场景。
PCIe 5.0的单通道速率达32GT/s,信号在主板走线和连接器之间的衰减极为严重。当PCIe链路长度超过一定距离(如通过背板或线缆连接远端设备时),信号质量的劣化将导致链路降速甚至不可用。联瑞电子PCIe Retimer扩展卡内置高性能信号中继器芯片,对PCIe 5.0信号进行重定时和均衡处理,恢复信号的完整性和时序精度,确保长距离PCIe链路在全速率下稳定运行。该方案是构建大型GPU服务器机箱和外部扩展柜时不可或缺的信号保障环节。
CXL(Compute Express Link)是基于PCIe物理层的新一代互联协议,支持主机CPU以缓存一致性方式访问外部扩展内存。联瑞电子CXL内存扩展卡使服务器可以在现有DDR5内存之外,通过PCIe插槽额外增加TB级内存容量,且CPU可像访问本地内存一样透明地访问CXL扩展内存。对于大模型推理场景,CXL内存扩展可将单台服务器的可用内存从2TB扩展到数十TB,无需对应用程序做任何修改即可加载更大规模的模型,显著降低推理延迟和多机通信开销。
以下为联瑞电子针对AI与高性能计算场景的核心产品矩阵,涵盖网络互联、GPU扩展、信号保障和存储加速四大类别:
此外,联瑞电子CXL内存扩展卡已进入量产阶段,支持CXL 2.0协议,可通过PCIe 5.0插槽为服务器扩展大容量、低延迟的外部内存,为大模型推理场景提供内存容量保障。如需了解CXL产品详情,欢迎联系联瑞电子技术团队获取最新资料。
网卡、Switch卡、Retimer卡、NVMe扩展卡均为联瑞电子自主研发设计,产品之间经过严格的互联互通测试,确保在同一服务器平台内各配件协同工作的稳定性和兼容性。一站式采购,统一技术支持,降低多供应商整合的风险和成本。
全系列产品兼容Intel Xeon、AMD EPYC等主流服务器平台,适配浪潮、华为、联想、新华三、超微等品牌服务器。同时完成了与NVIDIA GPU、AMD Instinct GPU的兼容性验证,可直接集成到现有AI服务器方案中。
联瑞电子配备专业的AI与HPC方案支持团队,提供从选型咨询、方案设计、部署调试到长期运维的全生命周期服务。响应时间不超过4小时,全国主要城市均设有技术服务网点,确保关键业务系统的持续稳定运行。
某互联网企业构建千卡级GPU训练集群,用于训练千亿参数大语言模型。采用联瑞电子LRES1260PF-2QSFP112 400G RDMA网卡作为节点间互联网络,搭配LRSV9500-4I PCIe 5.0 Switch卡(Broadcom PEX89048芯片)扩展单节点NVMe存储与GPU设备数量。部署后,AllReduce通信延迟降低65%,整体训练吞吐提升约40%,GPU利用率从62%提升至87%。
某云服务商搭建多租户AI推理平台,服务于图像识别、自然语言处理等在线推理业务。采用LRES1080PF-2QSFP56 100G网卡构建前端接入网络,以LRNV9541-4IR 4口M.2 NVMe阵列卡(支持RAID 0/1/JBOD)加速模型加载与检查点存储。CXL内存扩展卡用于承载超大推理模型的内存需求,单台服务器可同时服务的并发推理请求数提升3倍。
某科研院所高性能计算中心用于气候模拟、分子动力学等科学计算任务。采用LRES1160PF-2QSFP56 200G RDMA网卡实现计算节点间的低延迟MPI通信,LRSV9560-2E PCIe 5.0 Retimer卡(澜起M88RT51632芯片,支持CXL 2.0协议)保障机柜间长距PCIe互联的信号质量。系统部署后,MPI延迟降低至2.1微秒,大规模并行任务的计算效率提升超过35%。
研发中心地址:深圳市龙岗区龙城街道远洋新天地T10栋14楼
制造中心地址:深圳市龙岗区龙岗街道新生绿谷1B栋9-11楼
邮 箱: info@lr-link.com
技术支持: 19924451883


 产品咨询
产品咨询 技术支持
技术支持
 服务电话
服务电话服务热线:
4000-588-108